Mowa nienawiści staje się coraz większym problemy w sieci. Badania jak ją ograniczyć m.in. z wykorzystaniem sztucznej inteligencji prowadzą naukowcy z Wydziału Informatyki i Telekomunikacji PWr. Na swoje prace otrzymali z NCN blisko 1,4 mln zł.

Projekt pt. „Spersonalizowane wnioskowanie w przetwarzaniu języka naturalnego” dofinansowano w ramach prowadzone przez Narodowe Centrum Nauki programu Opus. Badaniami kieruje prof. Przemysław Kazienko z Katedry Sztucznej Inteligencji.
Mowa nienawiści, czyli co?
– W dobie powszechnego dostępu do Internetu, każdy użytkownik może stać się kreatorem treści i swobodnie wyrażać swoje poglądy. Złudzenie anonimowości powoduje jednak, że część osób bezrefleksyjnie tworzy treści obraźliwe, atakujące oraz pełne nienawiści – mówi prof. Przemysław Kazienko. – Obraźliwość tekstu jest zjawiskiem bardzo subiektywnym i trudno określić granicę dopuszczalności swobody wypowiedzi, by usatysfakcjonować zarówno twórców opinii, jak i ich odbiorców – dodaje.
Czym więc jest mowa nienawiści? W dużym skrócie to wszystkie formy ekspresji, które rozpowszechniają, podżegają, wspierają lub usprawiedliwiają nienawiść rasową, religijną, ksenofobię, antysemityzm lub inne formy nienawiści wynikające z nietolerancji.
Trzeba przy tym pamiętać, że prawo dotyczące takich wpisów w Internecie jest bardzo zróżnicowane i zależne od kraju. Istnieją takie państwa, gdzie mowa nienawiści jest przestępstwem, jednak z drugiej strony, w bardzo wielu przypadkach definicja takiej mowy nie jest precyzyjna. Wielu właścicieli mediów społecznościowych jest w związku z tym zmuszona cenzurować treści, które uznają za obraźliwe.
– Niekiedy nosi to znamiona cenzury, gdyż proste algorytmy, bazujące na słowach kluczowych, są w stanie blokować także użytkowników, którzy w sposób kulturalny zabierają głos w tematach kontrowersyjnych. Często dochodzi też do zwyczajnej pomyłki. Frustrację części użytkowników budzi też fakt, że ich potrzeby i uczucia są poddawane krytyce w przestrzeni publicznej, nie są prawnie chronione, podczas gdy inne grupy społeczne są w tym aspekcie traktowane wyjątkowo – tłumaczy naukowiec.
 Jak rozpoznać mowę nienawiści?
Jak rozpoznać mowę nienawiści?
Efektem takich działań jest tworzenie i wykorzystywanie algorytmów, które w sposób automatyczny decydują, czy dany tekst jest np. obraźliwy. Większość prac z tej tematyki jest rozwijana w ramach przetwarzania języka naturalnego (ang. Natural Language Processing, NLP) i jest tam od dawna znana pod nazwą klasyfikacji tekstu.
Chociaż istnieje wiele gotowych rozwiązań w tej dziedzinie, to jednak do tej pory zadania algorytmów koncentrowały się przede wszystkim w obszarach o dużym stopniu obiektywności np. rozpoznawanie języka tekstu, dziedziny czy stylu funkcjonalnego. W takich zadaniach praktycznie nie ma kontrowersji, a ręcznie oznaczane zbiory danych charakteryzują się wysokim poziomem zgodności decyzji pomiędzy ekspertami.
– Zupełnie inaczej wygląda sytuacja ze zjawiskami subiektywnymi, np. rozpoznawanie mowy nienawiści, obraźliwości, toksyczności, humoru, emocji czy wydźwięku. Obecnie znane techniki, stosują np. głosowanie osób na daną interpretację, modelując w ten sposób decyzję większościową – wyjaśnia prof. Przemysław Kazienko.
Drugi popularny nurt zakłada tworzenie wytycznych, w których określa się, co osoby mają uznawać np. za treść obraźliwą. Metody te nie uwzględniają jednak wrażliwości konkretnych osób. Systemy budowane na podstawie tak przygotowanych narzędzi, wykazują się stronniczością względem konkretnych grup społecznych lub poglądów.
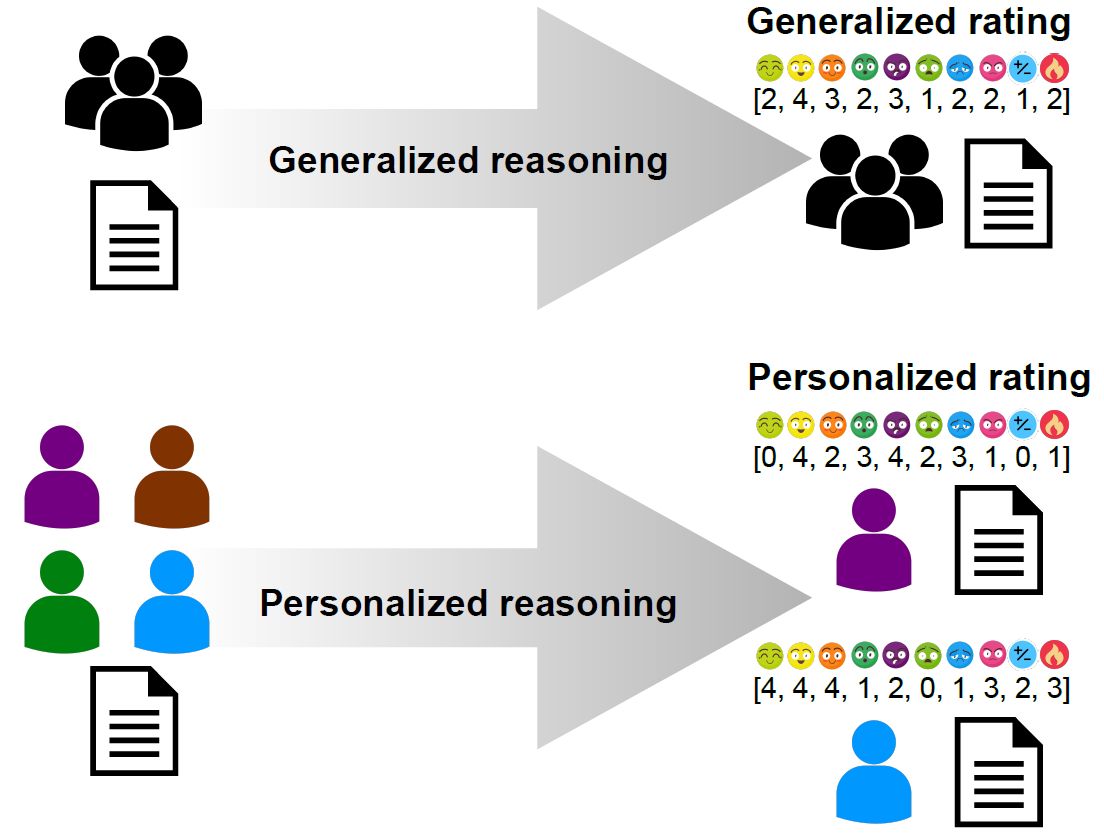
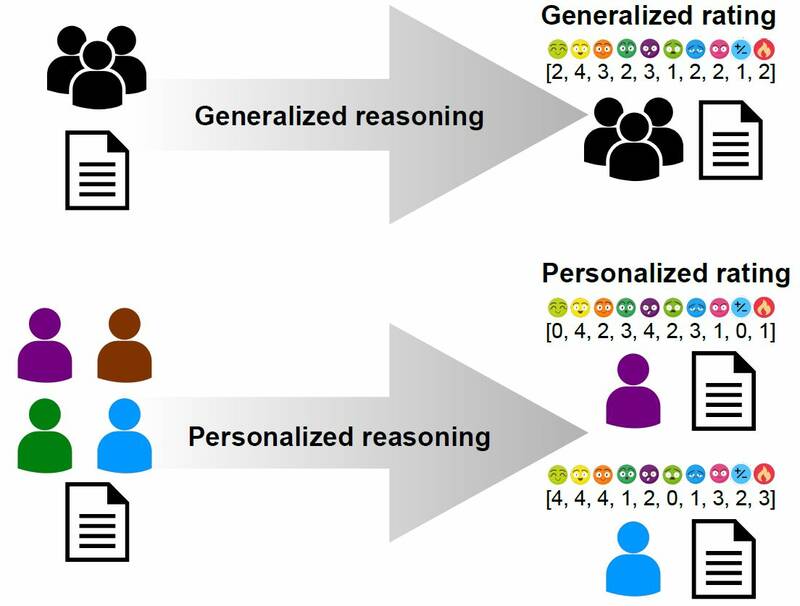
Personalizacja rozwiązań
– My w naszych badaniach proponujemy zupełnie nowe podejście do tego tematu, które jest zainspirowane osiągnięciami znanymi z systemów rekomendacyjnych. Nasze rozwiązania będą uwzględniać osobowość i poglądy konkretnej osoby, zarówno w trakcie przygotowywania modelu, jak i podczas podejmowania decyzji – podkreśla prof. Przemysław Kazienko.
Nasi naukowcy chcą więc opracować i przetestować nowe modele głębokiego uczenia maszynowego (sztucznej inteligencji), a wcześniej pozyskać odpowiednie, niedostępne jeszcze na świecie zbiory danych. Dodatkowo chcą rozszerzać istniejące rozwiązania o mechanizm rozumienia treści i uczenia reprezentacji człowieka z wykorzystaniem zarówno treści, jak i potencjalnego kontekstu jej występowania.
Różnica pomiedzy wnioskowaniem ogólnym i spersonalizowanym - grafikaW swojej pracy wykorzystają m.in. opracowane na PWr w ramach projektu CLARIN narzędzia związane z przetwarzaniem języka naturalnego.
– Opracowane metody będą w stanie odpowiedzieć np. dla kogo dana treść może być obraźliwa, a nie tylko czy jest ona ogólnie obraźliwa. Powstałe rozwiązania umożliwią więc użytkownikom mediów społecznościowych indywidualny wybór, czy chcą lub nie chcą czytać treści danego rodzaju – zaznacza prof. Przemysław Kazienko. – Pozwolą zatem na filtrowanie z perspektywy konkretnego człowieka, zaś system będzie się uczyć indywidualnych preferencji na podstawie naszych wcześniejszych decyzji – dodaje.
Warto podkreślić, że nowe rozwiązanie będzie można wdrożyć także dla wszystkich zjawisk subiektywnych, w których różnice w odbiorze między ludźmi są czymś naturalnym, np. ocena obraźliwości, toksyczności, agresji, ataku osobistego, mowy nienawiści, mowy wspierającej i przekonywującej, poczucia humoru, cyberbullingu, sarkazmu i ironii, oszczerstwa, niesmacznych pytań i przewidywania różnych emocji wywoływanych przez treści tekstowe.
– Można także założyć, że potencjał komercjalizacji naszych badań będzie spory. Powstaną serwisy, usługi związane z wnioskowaniem (klasyfikacją) treści tekstowych w spersonalizowany sposób. Pierwsze będą już za kilka miesięcy – zapowiada prof. Przemysław Kazienko.
Całość zadań przewidzianych w projekcie będzie realizowana na PWr, jednak nasi naukowcy chcą także współpracować z innymi zagranicznymi ośrodkami – University of Notre Dame (USA), University of California Los Angeles (UCLA, USA) oraz University of Wolverhampton (UK).
Projekt rozpisany został na cztery lata, a wysokość grantu przyznanego przez NCN wynosi blisko 1,4 mln zł.
Galeria zdjęć